Learning procedure¶
We work with numerically generated training trajectories that we denote by
To obtain an approximation of the Hamiltonian \(H\), we define a parametric model \(H_{\Theta}\) and look for a \(\Theta\) so that the trajectories generated by \(H_{\Theta}\) resemble the given ones. \(H_{\Theta}\) in principle can be any parametric function depending on the parameters \(\Theta\). In our approach, \(\Theta\) will collect a factor of the mass matrix and the weights of a neural network, as described below. We use some numerical one-step method \(\Psi_{X_{H_{\Theta}}}^{\Delta t}\) to generate the trajectories
We then optimize a loss function measuring the distance between the given trajectories \(y^j_i\) and the generated ones \(\hat{y}_i^j\), defined as
where \(\|\cdot\|\) is the Euclidean metric of \(\mathbb{R}^{2n}\). This is implemented with the PyTorch \(\texttt{MSELoss}\) loss function. Such a training procedure resembles the one of Recurrent Neural Networks (RNNs), as shown for the forward pass of a single training trajectory in the following figure.
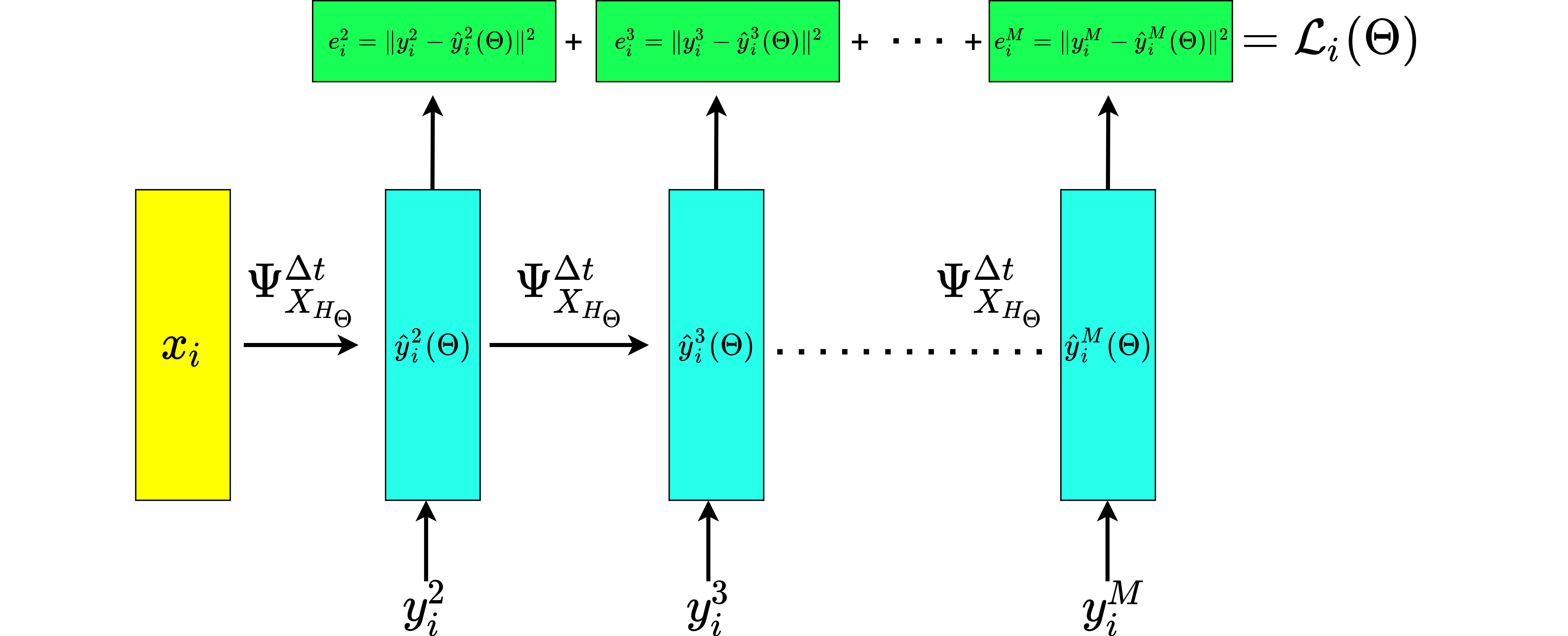
Figure 1. Forward pass of an input training trajectory \((x_i,y_i^2,...,y_i^M)\). The picture highlights the resemblance to an unrolled version of a Recurrent Neural Network. The network outputs \((\hat{y}_i^2,…,\hat{y}_i^M)\).¶
Indeed, the weight sharing principle of RNNs is reproduced by the time steps in the numerical integrator which are all based on the same approximation of the Hamiltonian, and hence on the same weights \(\Theta\).
Architecture of the network¶
In this example, the role of the neural network is to model the Hamiltonian, i.e. a scalar function defined on the phase space \(\mathbb{R}^{2n}\). Thus, the starting and arrival spaces are fixed.
We leverage the form of the kinetic energy, where \(M(q)\) is modelled through a constant symmetric and positive definite matrix with entries \(m_{ij}\). Therefore, we aim at learning a constant matrix \(A\in\mathbb{R}^{k\times k}\) and a vector \(b\in\mathbb{R}^k\) so that
where \(\tilde{b}_i := \max{(0,b_i)}\) are terms added to promote the positive definiteness of the right-hand side. Notice that, in principle, the imposition of the positive (semi)definiteness of the matrix defining the kinetic energy is not necessary, but it allows to get more interpretable results. Indeed, it is known that the kinetic energy should define a metric on \(\mathbb{R}^n\) and the assumption we are making guarantees such a property. For the potential energy, a possible modelling strategy is to work with standard feedforward neural networks, and hence to define
for example with \(\sigma(x) = \tanh(x)\). Therefore, we have that
The neural network for the parameterized Hamiltonian (8) is defined in the following PyTorch class.
- class Learning_Hamiltonians.main.Hamiltonian¶
Class to define the neural network (parameterized Hamiltonian), which inherits from nn.Module
- __init__()¶
Method where the parameters are defined
- MassMat(X)¶
Mass matrix defining the kinetic energy quadratic function
- Parameters:
X (torch.Tensor) – training trajectory points in input, with shape [batch size, nop*2s]
- Returns:
row – Mass matrix to be learned by the neural network, with shape [batch size, nop*s, nop*s]
- Return type:
torch.Tensor
- Kinetic(X)¶
Kinetic energy in the Hamiltonian function
- Parameters:
X (torch.Tensor) – training trajectory points in input, with shape [batch size, nop*2s]
- Returns:
row – Kinetic energy, with shape [batch size, 1]
- Return type:
torch.Tensor
- Potential(X)¶
Potential energy in the Hamiltonian function
- Parameters:
X (torch.Tensor) – training trajectory points in input, with shape [batch size, nop*2s]
- Returns:
row – Potential energy, with shape [batch size, 1]
- Return type:
torch.Tensor
- forward(X)¶
Forward function that receives a tensor containing the input (trajectory points in the phase space) and returns a tensor containing a scalar output (Hamiltonian)).
- Parameters:
X (torch.Tensor) – training trajectory points in input, with shape [batch size, nop*2s]
- Returns:
o – Value of the Hamiltonian, with shape [batch size, 1]
- Return type:
torch.Tensor